
目录
什么是编译
一、语言及编译
编译:将高级语言(源语言) 翻译成 汇编语言或机器语言(目标语言) 的过程
高级语言 x = 2
|
| 编译(Compiling)
↓
汇编语言 MOV X, 2
|
| 汇编(Assembling)
↓
机器语言 C706 0000 0002
二、编译过程
源程序
|
| 预处理器(Preprocessor)
↓
经过预处理的源程序
|
| 编译器(Compiler)
↓
汇编语言程序
|
| 汇编器(Assembler)
↓
可重定位的机器代码
|
| 链接器(Linker)/ 加载器(Loader)
↓
目标机器代码
预处理器(Preprocessor)
把存储在不同文件中的源程序聚合在一起。
把被称为宏的缩写语句转换为原始语句。
可重定位机器代码
可重定位(Relocatable):在内存中存放的起始位置L不是固定的。
加载器(Loader)
修改可重定位地址,将修改后的指令和数据放到内存中适当的位置
链接器(Linker)
将多个可重定位的机器 代码文件(包括库文件) 连接到一起
解决外部内存地址问题
目标机器代码
起始位置 +相对地址=绝对地址
三、编译系统结构
-------------------------------
| 字符流 |
| | |
| | 词法分析起 |
| ↓ |
| 词法单元流 |
| | |
| | 语法分析器 |
| ↓ |
分析部分 | 语法树 |
前端(front end) | | |
与源语言相关 | | 语义分析器 |
| ↓ |
| 语法树 |
| | |
| | 中间代码生成器 |
| ↓ |
| 中间表示形式 |
| | |
-----------|-------------------- |
| 机器无关代码优化器
↓
中间表示形式
|----------|--------------------|
| | 目标代码生成器 |
| ↓ |
综合部分 | 目标机器语言 |
后端(back end) | | |
与目标语言相关 | | 机器相关代码优化器 |
| ↓ |
| 目标机器语言 |
| |
---------------------------------
词法分析
介绍
从左向右逐行扫描源程序的字符,识别出各个单词,转为为词法单元(token)形式。
token:< 种别码,属性值 >
| 单词类型 | 种别 | 种别码 |
|---|---|---|
| 1 关键字 | program, if, else, then, … | 一词一码 |
| 2 标识符 | 变量名、数组名、记录名、过程名、… | 多词一码 |
| 3 常量 | 整型、浮点型、字符型、布尔型、… | 一型一码 |
| 4 运算符 | 算术(+ - * / ++ -) 关系(> < == != >= <=) 逻辑(& | ~) |
一词一码 或 一型一码 |
| 5 界限符 | ;()={}… | 一词一码 |
while(value!=100){num++;}
1 while < WHILE , - >
2 ( < SLP , - >
3 value < IDN , value >
4 != < NE , - >
5 100 < CONST , 100 >
6 ) < SRP , - >
7 { < LP , - >
8 num < IDN , num >
9 ++ < INC , - >
10 ; < SEMI , - >
11 } < RP , - >
position = initial + rate * 60 ;
<id, position> <=> <id,initial> <+> <id, rate> <*> <num,60> <;>
二、具体说明
在词法分析(Lexical Analysis)中:
关键字(keyword)、标识符(identifier)、运算符(operator)、界符(delimiter) 等 都是语言规范中明确规定的 Token 规则。
例如 C 语言定义:
if、for 是关键字
[_a-zA-Z][_a-zA-Z0-9]* 是标识符
+, -, *, / 是运算符
(, ) 是界限符
如果代码中的字符无法匹配任何 Token 规则 → 词法分析失败
例如:
int a = 1 # 2;
# 在 C 中不是合法 Token
比如届符 分号使用了 中文符号。
词法错误(Lexical Error)
总结
按语言规定的 Token 规则(关键字、运算符、界符、标识符等)将字符流切分为 Token。
若字符序列无法匹配任何 Token 规则 → 词法分析失败。
语法分析
一、介绍
语法分析器(parser)从词法分析器输出的token序列中,识别出各类短语,并构造语法分析树(parse tree)
将token序列,按照文法规则,转换为语法树
二、具体说明
一门语言规定了很多种 上下文无关文法(CFG),这些文法就是这门语言的语法规范。
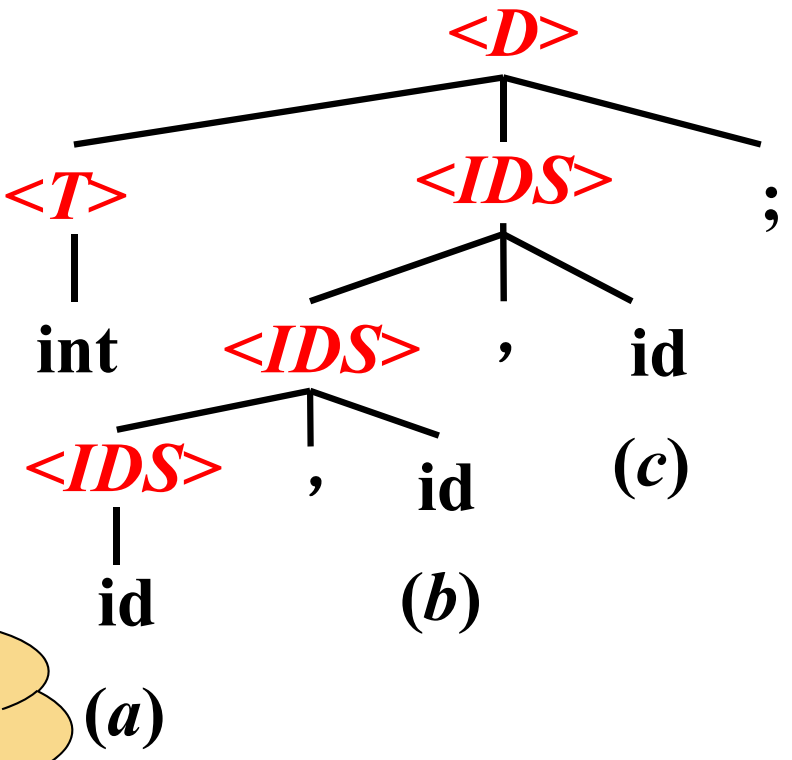
比如:变量声明
输入:
int a , b , c
token
<int> <id,a> <,> <id,b> <,> <id,c><;>
变量声明的文法
文法:
<D> → <T> <IDS>;
<T> → int | real | char | bool
<IDS> → id | <IDS>, id
根据语法规则,构建语法树
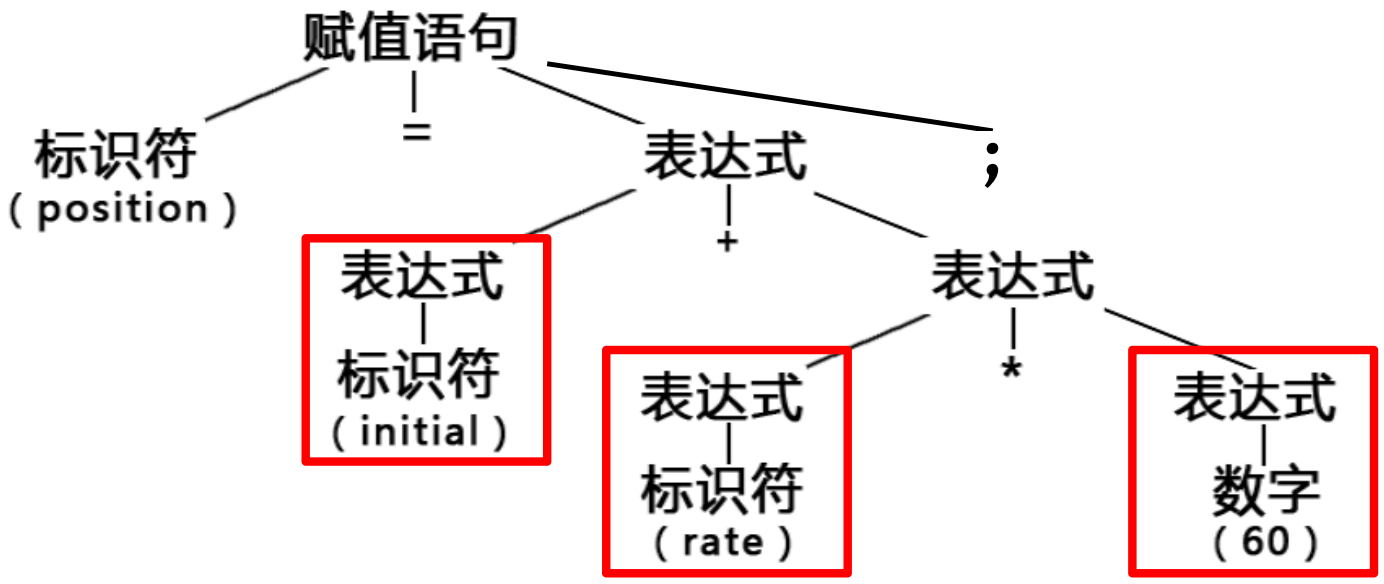
比如:赋值语句
输入:
position = initial + rate * 60 ;
token
<id, position> <=> <id,initial> <+> <id, rate> <*> <num,60> <;>
赋值语句的文法
根据语法规则,构建语法树
三、总结
使用文法(CFG)判断 Token 序列是否组成语言允许的结构(如声明、表达式、赋值等)。
若 Token 序列无法匹配任何文法规则 → 语法分析失败。
文法就是这门语言的语法规范。
语法分析确保程序结构正确
语义分析
一、介绍
语义分析确保程序逻辑正确
二、具体说明
语义分析的主要任务
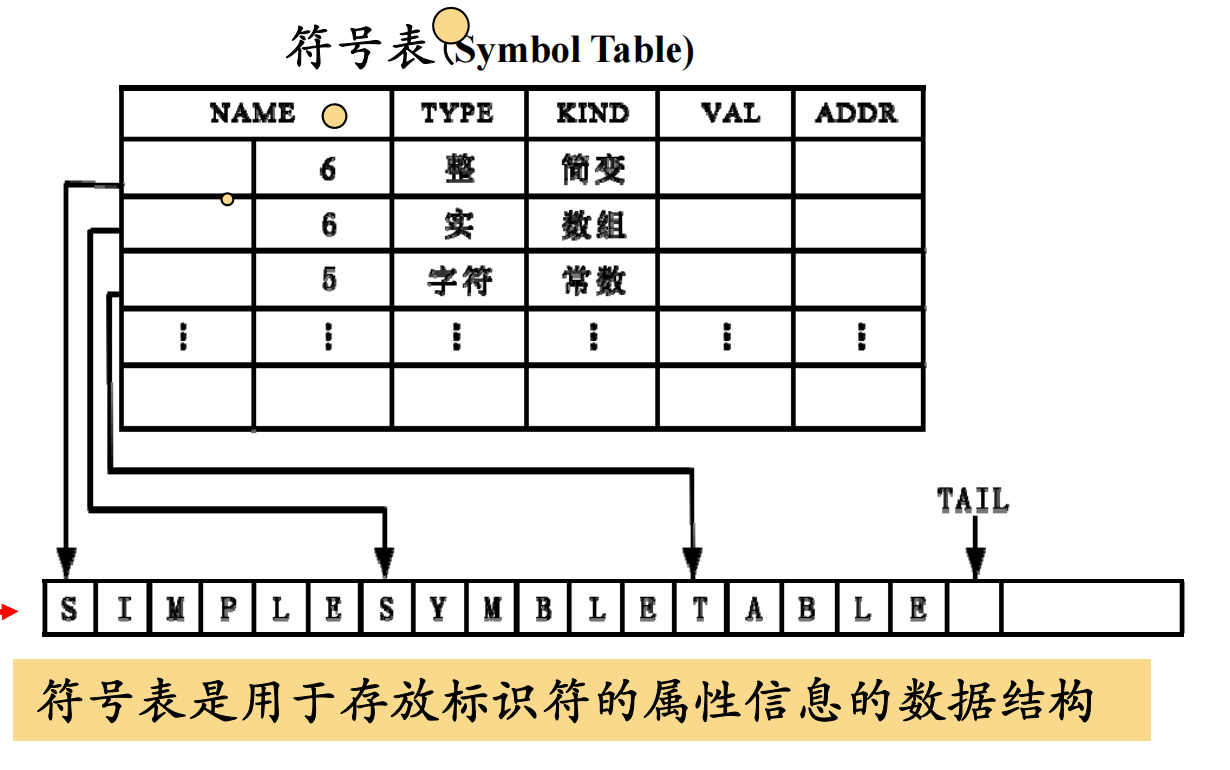
1、通过遍历语法树,收集标识符的属性信息,构建符号表。
符号表记录了,所有标识符(变量、函数、类等)信息的数据结构。
通常,它是一个 作用域嵌套的表结构(Scope Stack)。
2、通过符号表进行语义检查(符号表存储了各种信息)
变量类型检查、函数匹配检查(参数,返回值)、运算符匹配检查等
符号表是整个语义分析的核心
中间代码生成
目标代码生成
目标代码生成以源程序的中间 表示形式作为输入,并把它映 射到目标语言
目标代码生成的一个重要任务 是为程序中使用的变量合理分 配寄存器
代码优化
为改进代码所进行的等价程序变换,使其运行得更快一些、占用空间更少一些,或者二者兼顾
比如,自动识别代码中的重复运算或冗余运算并将它们删除
再比如,把代价较高的运算替换为代价较低的等价运算
Nothing is impossible to a willing heart!