
目录
TreeMap分析
◼ 时间复杂度(平均)
添加、删除、搜索:O(logn)
◼ 特点
Key 必须具备可比较性
元素的分布是有顺序的
◼ 在实际应用中,很多时候的需求
Map 中存储的元素不需要讲究顺序
Map 中的 Key 不需要具备可比较性
◼ 不考虑顺序、不考虑 Key 的可比较性,Map 有更好的实现方案,平均时间复杂度可以达到 O(1)
那就是采取哈希表来实现 Map
哈希表
一、设计一个需求
设计一个写字楼通讯录,存放所有公司的通讯信息
座机号码作为 key(假设座机号码最长是 8 位),公司详情(名称、地址等)作为 value
添加、删除、搜索的时间复杂度要求是 O(1)
| 索引 | 数据 |
| 01 | |
| … | |
| 40089008 | 百度 |
| … | |
| 68485438 | 阿里 |
| … | |
| 99999999 |
存在什么问题?
空间复杂度非常大
空间使用率极其低,非常浪费内存空间
其实数组 companies 就是一个哈希表,典型的【空间换时间】
二、哈希表 Hash Table
◼ 哈希表也叫做散列表( hash 有“剁碎”的意思)
◼ 它是如何实现高效处理数据的?
put(“Jack”, 666);
put(“Rose”, 777);
put(“Kate”, 888);
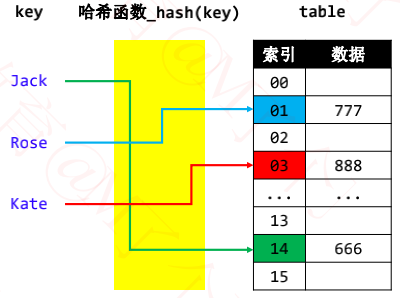
◼ 添加、搜索、删除的流程都是类似的
- 利用哈希函数生成 key 对应的 index【O(1)】
- 根据 index 操作定位数组元素【O(1)】
◼ 哈希表是【空间换时间】的典型应用
◼ 哈希函数,也叫做散列函数
◼ 哈希表内部的数组元素,很多地方也叫 Bucket(桶),整个数组叫 Buckets 或者 Bucket Array
三、哈希冲突
◼ 哈希冲突也叫做哈希碰撞
2 个不同的 key,经过哈希函数计算出相同的结果
key1 ≠ key2 ,hash(key1) = hash(key2)
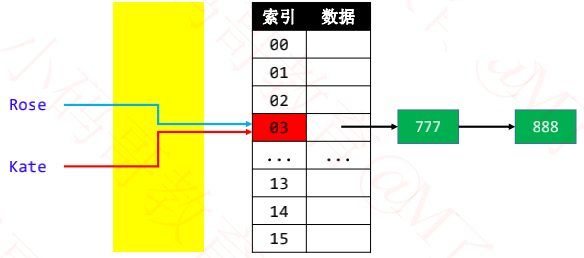
◼ 解决哈希冲突的常见方法
- 开放定址法(Open Addressing)
✓ 按照一定规则向其他地址探测,直到遇到空桶 - 再哈希法(Re-Hashing)
✓ 设计多个哈希函数 - 链地址法(Separate Chaining)
✓ 比如通过链表将同一index的元素串起来
四、解决哈希冲突的方案
◼ 默认使用单向链表将元素串起来
◼ 在添加元素时,可能会由单向链表转为红黑树来存储元素
比如当哈希表容量 ≥ 64 且 单向链表的节点数量大于 8 时
◼ 当红黑树节点数量少到一定程度时,又会转为单向链表
◼ JDK1.8中的哈希表是使用链表+红黑树解决哈希冲突
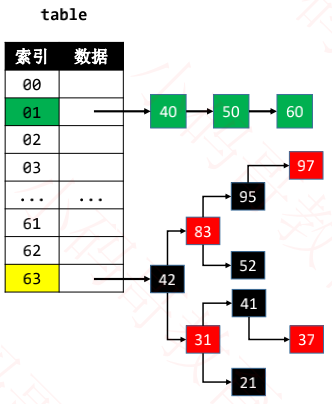
◼ 思考:这里为什么使用单链表?
每次都是从头节点开始遍历
单向链表比双向链表少一个指针,可以节省内存空间
哈希函数
◼ 哈希表中哈希函数的实现步骤大概如下
- 先生成 key 的哈希值(必须是整数)
- 再让 key 的哈希值跟数组的大小进行相关运算,生成一个索引值

◼ 为了提高效率,可以使用 & 位运算取代 % 运算【前提:将数组的长度设计为 2 的幂(2^n)】

◼ 良好的哈希函数
让哈希值更加均匀分布 → 减少哈希冲突次数 → 提升哈希表的性能
哈希值
◼ key 的常见种类可能有
整数、浮点数、字符串、自定义对象
不同种类的 key,哈希值的生成方式不一样,但目标是一致的
✓ 尽量让每个 key 的哈希值是唯一的
✓ 尽量让 key 的所有信息参与运算
◼ 在Java中,HashMap 的 key 必须实现 hashCode、equals 方法,也允许 key 为 null
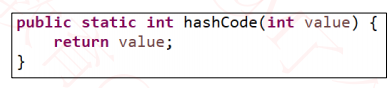
一、整数的哈希值
整数值当做哈希值
比如 10 的哈希值就是 10
二、浮点数的哈希值
将存储的二进制格式转为整数值

三、Long和Double的哈希值

◼ > > > 和 ^ 的作用是?
高32bit 和 低32bit 混合计算出 32bit 的哈希值
充分利用所有信息计算出哈希值

四、字符串的哈希值
◼ 整数 5489 是如何计算出来的?
5 ∗ 10^3 + 4 ∗ 10^2 + 8 ∗ 10^1 + 9 ∗ 10^0
◼ 字符串是由若干个字符组成的
比如字符串 jack,由 j、a、c、k 四个字符组成(字符的本质就是一个整数)
因此,jack 的哈希值可以表示为 j ∗ n^3 + a ∗ n^2 + c ∗ n^1 + k ∗ n^0,等价于 [ ( j ∗ n + a ) ∗ n + c ] ∗ n + k
在JDK中,乘数 n 为 31,为什么使用 31?
✓ 31 是一个奇素数,JVM会将 31 * i 优化成 (i « 5) – i

关于31的探讨
◼ 31 * i = (2^5 – 1) * i = i * 2^5 – i = (i « 5) – i
◼ 31不仅仅是符合2^n – 1,它是个奇素数(既是奇数,又是素数,也就是质数)
素数和其他数相乘的结果比其他方式更容易产成唯一性,减少哈希冲突
最终选择31是经过观测分布结果后的选择
五、自定义对象的哈希值

自定义对象作为key
◼ 自定义对象作为 key,最好同时重写 hashCode 、equals 方法
equals :用以判断 2 个 key 是否为同一个 key
✓ 自反性:对于任何非 null 的 x,x.equals(x)必须返回true
✓ 对称性:对于任何非 null 的 x、y,如果 y.equals(x) 返回 true,x.equals(y) 必须返回 true
✓ 传递性:对于任何非 null 的 x、y、z,如果 x.equals(y)、y.equals(z) 返回 true,那么x.equals(z) 必须返回 true
✓ 一致性:对于任何非 null 的 x、y,只要 equals 的比较操作在对象中所用的信息没有被修改,多次调用x.equals(y) 就会一致地返回 true,或者一致地返回 false
✓ 对于任何非 null 的 x,x.equals(null) 必须返回 false
hashCode :必须保证 equals 为 true 的 2 个 key 的哈希值一样
反过来 hashCode 相等的 key,不一定 equals 为 true
◼ 不重写 hashCode 方法只重写 equals 会有什么后果?
✓ 可能会导致 2 个 equals 为 true 的 key 同时存在哈希表中
六、哈希值的进一步处理
处理哈希值的目的:是哈希值尽可能的均匀分布,减少产生索引的碰撞。
1、扰动计算

为什么要进行扰动计算,避免导致哈希碰撞的概率较大。
比如 table.length = 2^16; table.length - 1 是 16 位的二进制数。那么 & 的结果必然是只取哈希值的前16位进行计算。
比如哈希值为:
0100 0000 0000 0000 1010 1010 1010 1010
0110 0000 0000 0000 1010 1010 1010 1010
如果没有扰动计算 这两个哈希值计算的索引相同,导致哈希碰撞
如果有扰动计算 这两个哈希值计算的索引不同,避免了哈希碰撞
采用这种方式对哈希表的长度有要求,必须是2^n。这样能保证table.length - 1转为二进制,每个位上都是1
2、采用%来处理哈希值
如果使用%来计算索引,建议把哈希表的长度设计为素数(质数),可以大大减小哈希冲突。(虽然%的计算效率较低,但素数具有神奇的性质)
| 10%8 = 2 | 10%7 = 3 |
| 20%8 = 4 | 20%7 = 6 |
| 30%8 = 6 | 30%7 = 2 |
| 40%8 = 0 | 40%7 = 5 |
| 50%8 = 2 | 50%7 = 1 |
| 60%8 = 4 | 60%7 = 4 |
| 70%8 = 6 | 70%7 = 0 |
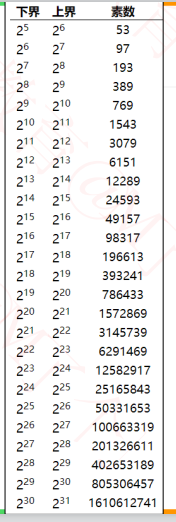
下边表格列出了不同数据规模对应的最佳素数,特点如下
每个素数略小于前一个素数的2倍
每个素数尽可能接近2的幂(2^n);
哈希表内的红黑树
一、红黑树节点比较
红黑树需要外部传入一个比较器,来决定添加或查找节点时,是向左进行还是向右进行。但哈希表并不需要传入比较器。这就带来一个问题,哈希表内部的红黑树如何来比较大小。
1、直接使用哈希值来比较是否可行?
key通过哈希计算产生哈希值,哈希值与桶长度计算得到索引。
哈希表:key相等 -> 哈希值相等 -> 索引相等。但反过来推不成立。
不同的key可能会产生相同的哈希值,不同哈希值可能会产生相同的索引。首先在同一棵树上的节点,key都不同,哈希值有的相同有的不同,但他们的哈希值计算出来的索引都相同。 当添加的新节点与树上的节点的哈希值不同时可以比较,但相同时并不能认定两个节点的key相等,此时就无法处理了。
2、通过compare来比较
首先需要key实现了compare,再者compare只能比较处大小,比较结果为0,只能认定两个key的大小相等,不能认定两个key相等。所以当key没有实现compare时,或者实现了但比较结果为0时,无法处理。
3、直接使用内存地址来比较是否可行?
当我们通过key的内存地址来比较大小时,任何两个key都可以比较处出大小,但找不出两个相等的key,因为每个key的内存地址都不同。
假设我们认定person1对象和person2对象,只要他们的身份证号相同就是同一个人。但他们的内存地址不同。这时就会出现同一个树上有多个相同的节点。这种情况内存地址无法处理。
4、内存地址和equal两个条件来判断
以上我们可以看出,都是在比较key是否相等时无法判断。那么我们先用内存地址比较来决定向左或是向右,用equal来比较是否相等是否可行呢?
新节点与树上的节点先判断是否equal,相等就替换,不相等就比较内存地址。假设右子树上存在与新节点相同的节点。当我们与根节点比较内存地址时,走向了左子树,此时就永远无法找到右子树上相同的节点,同样会出现同一棵树上存在多个相同的节点。
5、最简单的红黑树比较方案
添加新节点,判断与根节点是否equal,相等就进行替换,不相等遍历左右子树查看是否存在相等节点。(遍历树查看是否有相等节点)
若不存在相等节点就直接放到右侧。
这样可以解决 1-4 存在的问题,但效率很差。每次添加新节点都要遍历。每次都添加到右侧 红黑树的调整比较频繁。
二、比较方案设计
考虑将以上几种情况融合到一起,在能判断时进行判断,不能判断是进行遍历。
/// 添加或修改键值对,返回旧value
/// @param key key
/// @param value value
-(id)putWithKey:(nonnull id)key value:(nullable id)value{
//扩容
[self __reSize];
NSUInteger index = [self __indexWithKey:key];
//获取key对应的root节点
LCHashMapNode * root = table[index];
if (root == [NSNull null]) {
root = [LCHashMapNode nodeWithKey:key value:value parent:nil];
table[index] = root;
self.size++;
[self afterAdd:root];
return nil;
}
LCHashMapNode * parent = root;
LCHashMapNode * node = root;
LCCompareType type = LCCompareEqual;
id k1 = key;
NSUInteger h1 = [self __raodongHash:k1];
LCHashMapNode* result = nil;
BOOL searched = false;//是否已经遍历过这个key,避免每次循环都遍历
do {
//在此处记录父节点
parent = node;
id k2 = node.key;
NSUInteger h2 = node.hash;
//1、先比较哈希值
if (h1<h2) {
type = LCCompareLess;
}else if(h1>h2){
type = LCCompareGreater;
//2、再比较是否相等
}else if([k1 isEqual:k2]){
/**
重要注意:
equal来确定是否相等
compare是比较大小,compare的比较的结果是0,并不能确定k1 与 k2 相等。只能说明大小相等。
比如两个兄弟,辈分相同,但并不是同一个人。
equal 与 compare 一定要区别开来,一个是比较相等,一个是比较大小。
*/
type = LCCompareEqual;
//3、再比较是否有可比较性
}else if(k1 && k2
&& [k1 isMemberOfClass:k2]
&& [k1 respondsToSelector:@selector(compare:)]
&& (type = (LCCompareType)[k1 compare:k2])!= LCCompareEqual){
/**
k1、k2具有可比较性,能比较出大小,就按比较结果处理。但比较大小相等时,不能认定为k1 与 k2相等。
*/
//4、能来到这里就是哈希值相等、不equal、不具备可比较性。已经比无可比了
}else if(searched){
//4-0、已经遍历过并且没有找到,直接比较内存地址
//没有找到key对应的节点
// NSString * kp1 = [NSString stringWithFormat:@"%p",k1];
// NSString * kp2 = [NSString stringWithFormat:@"%p",k2];
// type = (LCCompareType)[kp1 compare:kp2];
//这里也可以选择一直向右,规则自己定
type = LCCompareGreater;
}else{
/**
以下几种情况都会来到此处:
k1 = nil && k1!= nil;
k1 !=nil && k2 = nil;
k1 !=nil && k2!=nil; && k1与k2不是同类型
k1 !=nil && k2!=nil; && k1与k2是同类型 && 不具备可比性
k1 !=nil && k2!=nil; && k1与k2是同类型 && 具备可比性 && 大小相等
*/
//4-1、先通过遍历节点,查看是否有相同的key
if (
((node.right!=nil && (result = [self __Node:node.right key:k1])!=nil))
||((node.left !=nil && (result = [self __Node:node.left key:k1])!=nil))
) {
//在右侧或者左侧找到了相同的节点
node = result;
type = LCCompareEqual;
searched = true;
//4-2、所有情况都比较完了,只能用内存地址比较了
}else{
//没有找到key对应的节点
// NSString * kp1 = [NSString stringWithFormat:@"%p",k1];
// NSString * kp2 = [NSString stringWithFormat:@"%p",k2];
// type = (LCCompareType)[kp1 compare:kp2];
//这里也可以选择一直向右,规则自己定
type = LCCompareGreater;
}
}
switch (type) {
case LCCompareLess:
node = node.left;
break;
case LCCompareGreater:
node = node.right;
break;
case LCCompareEqual:{
id oldValue = node.value;
node.key = key;
node.value = value;
return oldValue;
break;
}
default:
break;
}
}while (node);
//如果能来到这里 node == nil; 所以应该在循环里记录下添加节点的父节点和比较结果
LCHashMapNode * addNode = [self creatNodeWithKey:key value:value parent:parent];
if (type == LCCompareLess) {
parent.left = addNode;
}else if(type ==LCCompareGreater){
parent.right = addNode;
}else if(type == LCCompareEqual){
}
_size++;
[self afterAdd:addNode];
return nil;
}
/// 通过key找到对应的node节点
/// @param key key
-(LCHashMapNode*)__Node:(id)key{
LCHashMapNode* root = table[[self __indexWithKey:key]];
return root == [NSNull null]?nil: [self __Node:root key:key];
}
/// 从一棵树内找到key对应的节点(通过传入的节点和key,找到key对应的节点)
/// @param node 开始查找的节点
/// @param k1 key
-(LCHashMapNode*)__Node:(LCHashMapNode*)node key:(id)k1{
NSUInteger h1 = [self __raodongHash:k1];
//存储查找结果
LCHashMapNode* result = nil;
LCCompareType type = LCCompareEqual;
while (node!=nil) {
id k2 = node.key;
NSUInteger h2 = node.hash;
//1、先比较哈希值
if (h1>h2) {
node = node.right;
}else if(h1<h2){
node = node.left;
//2、再比较是否相等
}else if((k1 == nil && k2 == nil) || [k1 isEqual:k2]){
//是否可以用下面写法代替
//k1==nil?k2==nil:[k1 isEqual:k2];
return node;
//3、再看是否具有可比较性
}else if(k1 && k2
&& [k1 isMemberOfClass:k2]
&& [k1 respondsToSelector:@selector(compare:)]
&& (type = (LCCompareType)[k1 compare:k2]) != LCCompareEqual){
node = (type == LCCompareGreater?node.right:node.left);
//4、不具备可比较性(递归遍历)
}else if(node.right!=nil && (result = [self __Node:node.right key:k1]) !=nil){
//在右侧找到
return result;
}else if(node.left!=nil && (result = [self __Node:node.left key:k1]) !=nil){
//在左侧找到
return result;
}else{
//没有找到
return nil;
}
}
return nil;
}
哈希表的扩容
装填因子(Load Factor):节点总数量 / 哈希表桶数组长度,也叫做负载因子
在JDK1.8的HashMap中,如果装填因子超过0.75,就扩容为原来的2倍
-(void)__reSize{
//装填因子<=0.75
if(1.0 * self.size / table.count <= DEFAULT_LOAD_FACTOR) return;
//保留旧的table
NSMutableArray* oldTable = table;
//扩容至以前的两倍
NSUInteger newCapacity = oldTable.count<<1;
table = [NSMutableArray arrayWithCapacity:newCapacity];
for (int i=0; i<newCapacity; i++) {
table[i] = [NSNull null];
}
NSLog(@"扩容至 %zd",table.count);
queue<LCHashMapNode*> queueNode;
for (int i = 0; i<oldTable.count; i++) {
if(oldTable[i] == [NSNull null]) continue;
queueNode.push(oldTable[i]);
while (queueNode.size()) {
LCHashMapNode* front = queueNode.front();
queueNode.pop();
if(front.left) queueNode.push(front.left);
if(front.right) queueNode.push(front.right);
//挪动代码得放到最后边
[self __moveNode:front];
}
}
}
-(void)__moveNode:(LCHashMapNode*)newNode{
//重置node
newNode.parent = nil;
newNode.left = nil;
newNode.right = nil;
newNode.color = RED;
NSUInteger index = [self __indexWithNode:newNode];
//获取对应的root节点
LCHashMapNode * root = table[index];
if (root == [NSNull null]) {
root = newNode;
table[index] = root;
[self afterAdd:root];
return;
}
LCHashMapNode * parent = root;
LCHashMapNode * node = root;
LCCompareType type = LCCompareEqual;
id k1 = newNode.key;
NSUInteger h1 = [self __raodongHash:k1];
do {
//在此处记录父节点
parent = node;
id k2 = node.key;
NSUInteger h2 = node.hash;
//1、先比较哈希值
if (h1<h2) {
type = LCCompareLess;
}else if(h1>h2){
type = LCCompareGreater;
}else if(k1 && k2
&& [k1 isMemberOfClass:k2]
&& [k1 respondsToSelector:@selector(compare:)]
&& (type = (LCCompareType)[k1 compare:k2])!= LCCompareEqual){
}else{
type = LCCompareGreater;
}
/**
为什么不需要equal判断和遍历,因为只是移动节点,肯定没有相同的节点存才
*/
switch (type) {
case LCCompareLess:
node = node.left;
break;
case LCCompareGreater:
node = node.right;
break;
default:
break;
}
}while (node);
//如果能来到这里 node == nil; 所以应该在循环里记录下添加节点的父节点和比较结果
if (type == LCCompareLess) {
parent.left = newNode;
}else if(type ==LCCompareGreater){
parent.right = newNode;
}
[self afterAdd:newNode];
}
行者常至,为者常成!