
目录
ASCII码
一、产生原因
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
二、规则
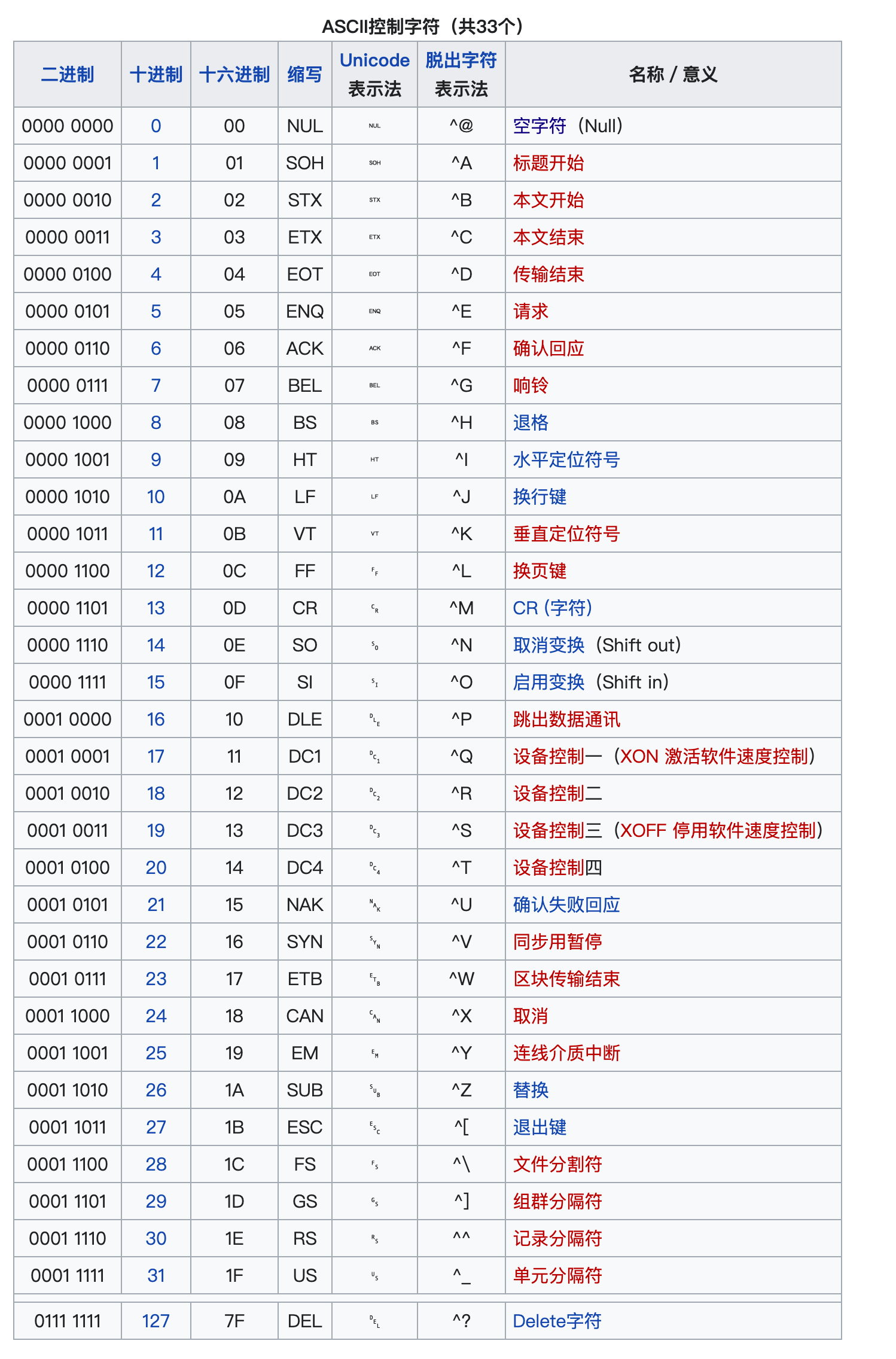
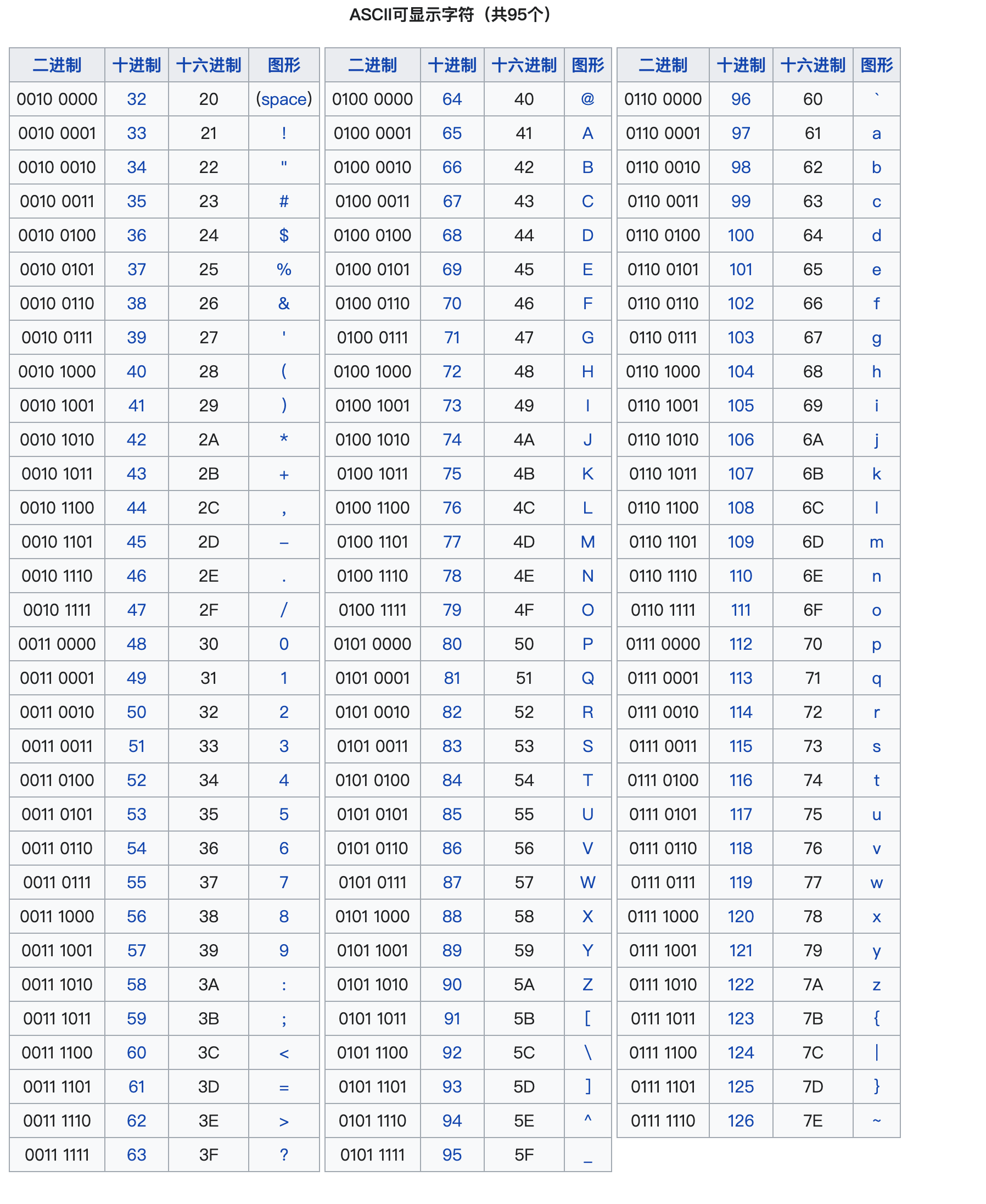
标准ASCII 码也叫基础ASCII码,使用7位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符 。其中:
0~31及127(共33个):是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响 。
32~126(共95个):是字符(32是空格),其中48~57为0到9十个阿拉伯数字。65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
Unicode
一、Unicode
Unicode 是一本很厚的字典,记录着世界上所有字符对应的一个数字。具体是怎样的对应关系,又或者说是如何进行划分的,就不是我们考虑的问题了,我们只用知道 Unicode 给所有的字符指定了一个数字用来表示该字符。
Unicode 仅仅只是一个字符集,就是为每个字符规定一个用来表示该字符的数字。规定了符合对应的二进制代码,至于这个二进制代码如何存储则没有任何规定。
原始字符串:这是一个例子,this is a example
unicode形式:\u8fd9\u662f\u4e00\u4e2a\u4f8b\u5b50,this is a example
二、UTF-8
UTF-8 是一个非常惊艳的编码方式,漂亮的实现了对 ASCII 码的向后兼容,以保证 Unicode 可以被大众接受。
UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。编码规则如下:
对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
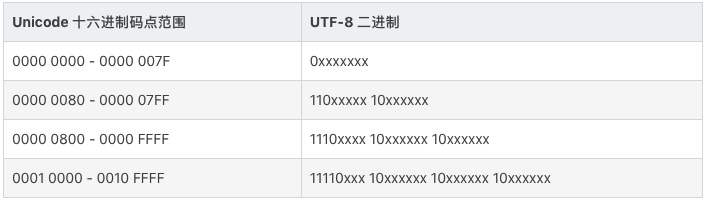
根据上面编码规则对照表,进行 UTF-8 编码和解码就简单多了。下面以汉字“汉”为利,具体说明如何进行 UTF-8 编码和解码。
“汉”的 Unicode 码点是 0x6c49(110 1100 0100 1001),通过上面的对照表可以发现,0x0000 6c49 位于第三行的范围,那么得出其格式为 1110xxxx 10xxxxxx 10xxxxxx。接着,从“汉”的二进制数最后一位开始,从后向前依次填充对应格式中的 x,多出的 x 用 0 补上。这样,就得到了“汉”的 UTF-8 编码为 11100110 10110001 10001001,转换成十六进制就是 0xE6 0xB7 0x89。
解码的过程也十分简单:如果一个字节的第一位是 0 ,则说明这个字节对应一个字符;如果一个字节的第一位1,那么连续有多少个 1,就表示该字符占用多少个字节。
‘\uff00’ 表示一个unicode形式的字符,unicode形式都是16进制的。
两者区别
Unicode是字符集:为每一个字符分配一个唯一的ID(学名为码位 / 码点 / Code Point)
UTF-8是编码规则:将码位转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
举一个例子:It’s 知乎日报
I 0049
t 0074
' 0027
s 0073
0020
知 77e5
乎 4e4e
日 65e5
报 62a5
每一个字符对应一个十六进制数字。
计算机只懂二进制,因此,严格按照unicode的方式(UCS-2),应该这样存储:
I 00000000 01001001
t 00000000 01110100
' 00000000 00100111
s 00000000 01110011
00000000 00100000
知 01110111 11100101
乎 01001110 01001110
日 01100101 11100101
报 01100010 10100101
这个字符串总共占用了18个字节,但是对比中英文的二进制码,可以发现英文前9位都是0!浪费啊,浪费硬盘浪费流量
用UTF-8表示
I 01001001
t 01110100
' 00100111
s 01110011
00100000
知 11100111 10011111 10100101
乎 11100100 10111001 10001110
日 11100110 10010111 10100101
报 11100110 10001010 10100101
和上边的方案对比一下,英文短了,每个中文字符却多用了一个字节。但是整个字符串只用了17个字节,比上边的18个短了一点点。
主要不同:
1、unicode是固定长度,utf-8是变长,节省存储空间,提高传输效率。
2、utf-8无字节序问题(在大端小端存储的机器上通用。xy:应为是一个字节一个字节的读取,所以不存在大小端问题)
行者常至,为者常成!